Vision & Goals
Win-Win Community in the Agent Era
True AGI is still a decade away. Agent is the essential path. Seize the wave to stay relevant.
Through deep practice, knowledge sharing, and project collaboration, break down technical barriers and transform them into personal advantages and real value.
Empower everyone, win the Agent decade.
What We Offer
- · Systematic learning paths and practice manuals
- · One-on-one guidance from technical mentors and industry experts
- · Paper notes, cutting-edge talks, case co-creation
- · Portfolio polishing, resume & interview coaching, referrals
Advanced Play
Deep Co-creation · Papers/Projects/Career Full Chain
If you want to get started with LLM Agents
- •Learning paths and open-source repo recommendations
- •Intro courses + hands-on projects
- •Like-minded exchange community
If you want further collaboration / papers / career
- •Paper collaboration and experiment co-building
- •Industry landing project cooperation
- •Big tech job referrals and interview coaching
If you seek partnerships
- •Co-build community brand
- •Joint promotion and events
- •AI product and training guidance
Learning & Exploration
Carefully curated learning resources to help you quickly master Agent core technologies
Advanced Path
Community Projects / Papers
Idea2Story
An Agent framework that automatically generates top-tier conference-level paper narratives from ideas. Trained on tens of thousands of top conference papers and their review data, teaching AI to master "Scientific Storytelling".
Talks & Roundtables · Paper Reading

OpenClaw-RL: 结合 GRPO + OPD,在使用中自适应变强的龙虾
在人工智能的发展进程中,我们正见证从纯粹的聊天机器人向能够执行实际任务的计算机使用智能体(Computer-Use Agents) 的范式转移。 OpenClaw-RL 是第一个通过对话自动训练工业级 Agent 的强化学习(RL)库,旨在让模型在真实的交互中实现自我进化。 一、 核心理念:随处部署
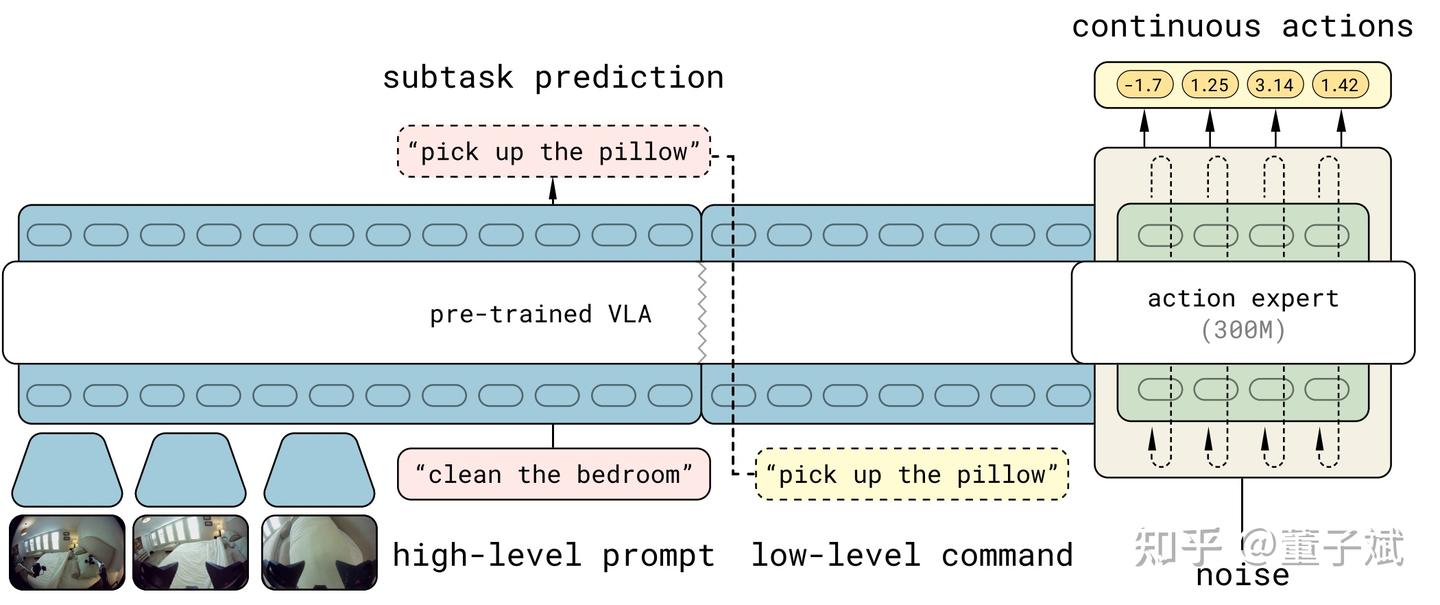
如何给 VLA 设计一个好的 Action Tokenizer?
作者:董子斌 https://zhuanlan.zhihu.com/p/2006493733990981927 1. 主流 VLA 架构以及为什么我们需要 action tokenizer 不得不承认 physical intelligence 依旧是 VLA 实践灯塔之一,自从 \pi_{0.5}
大模型的下半场是什么?林俊旸:从 Reasoning Thinking 到 Agentic Thinking
林俊旸在x上发了一篇长文,特此分享 https://x.com/JustinLin610/status/2037116325210829168 过去这两年,彻底颠覆了我们评估和期待大模型的方式。 OpenAI 的 o1 告诉我们:思考本身就能成为模型一种核心的一等能力,你可以专门为了思考去训练模型,

深度对话!2025 "青稞" AI 嘉年华,与 20+ 位青年科学家一起探讨AI 技术瞬间
本次活动专为青年科学家打造,旨在搭建一场 AI 技术的深度对话,来自学术和工业界的 20+ 青年科学家,将与大家一起回顾 2025,展望 2026!

TRPO重生:大模型时代的信任域策略优化
在大型语言模型的强化学习阶段,特别是RLHF中,我们追求策略的持续优化。本次分享深入探讨TRPO在LLM时代的应用。

从 π_0 到 π_RL:面向流匹配 VLA 的强化学习后训练框架
深入解析流匹配VLA的强化学习后训练框架π_RL,探索具身智能的前沿技术。

RLinf:面向具身智能的"渲训推一体化"开源强化训练框架
开源强化训练框架RLinf,实现渲染、训练、推理一体化,加速具身智能研发。

RLinf-VLA 实践:从零上手 VLA(OpenVLA)强化学习
手把手教你使用RLinf-VLA框架进行OpenVLA强化学习实践,入门具身智能开发。
深度对话!2025 "青稞" AI 嘉年华,与 20+ 位青年科学家一起探讨AI 技术瞬间
本次活动专为青年科学家打造,旨在搭建一场 AI 技术的深度对话,来自学术和工业界的 20+ 青年科学家,将与大家一起回顾 2025,展望 2026!
TRPO重生:大模型时代的信任域策略优化
在大型语言模型的强化学习阶段,特别是RLHF中,我们追求策略的持续优化。本次分享深入探讨TRPO在LLM时代的应用。
从 π_0 到 π_RL:面向流匹配 VLA 的强化学习后训练框架
深入解析流匹配VLA的强化学习后训练框架π_RL,探索具身智能的前沿技术。
RLinf:面向具身智能的"渲训推一体化"开源强化训练框架
开源强化训练框架RLinf,实现渲染、训练、推理一体化,加速具身智能研发。
RLinf-VLA 实践:从零上手 VLA(OpenVLA)强化学习
手把手教你使用RLinf-VLA框架进行OpenVLA强化学习实践,入门具身智能开发。
Join Us
Foundation Mastery
LLM/Multimodal fundamentals, code skills enhancement and engineering standards
Agent Architecture
Planning/Memory/Tool calling and evaluation, real business case breakdown
Project Co-creation
Hands-on project teaming, mentor Q&A and code review
Career Leap
Portfolio polishing, interview workshops, mentor recommendations and referrals
Deep Practice + Mentor Q&A + Project Co-creation
Portfolio polishing, code review, weekly retrospectives, referral recommendations. Limited spots per cohort to ensure interaction quality.
Partnership & Consultation
WeChat Official Account: AgentAlpha
Co-build community / Promotion partnerships / AI products / Training guidance, or need paper, project, career support, scan QR code to follow official account for more info.








